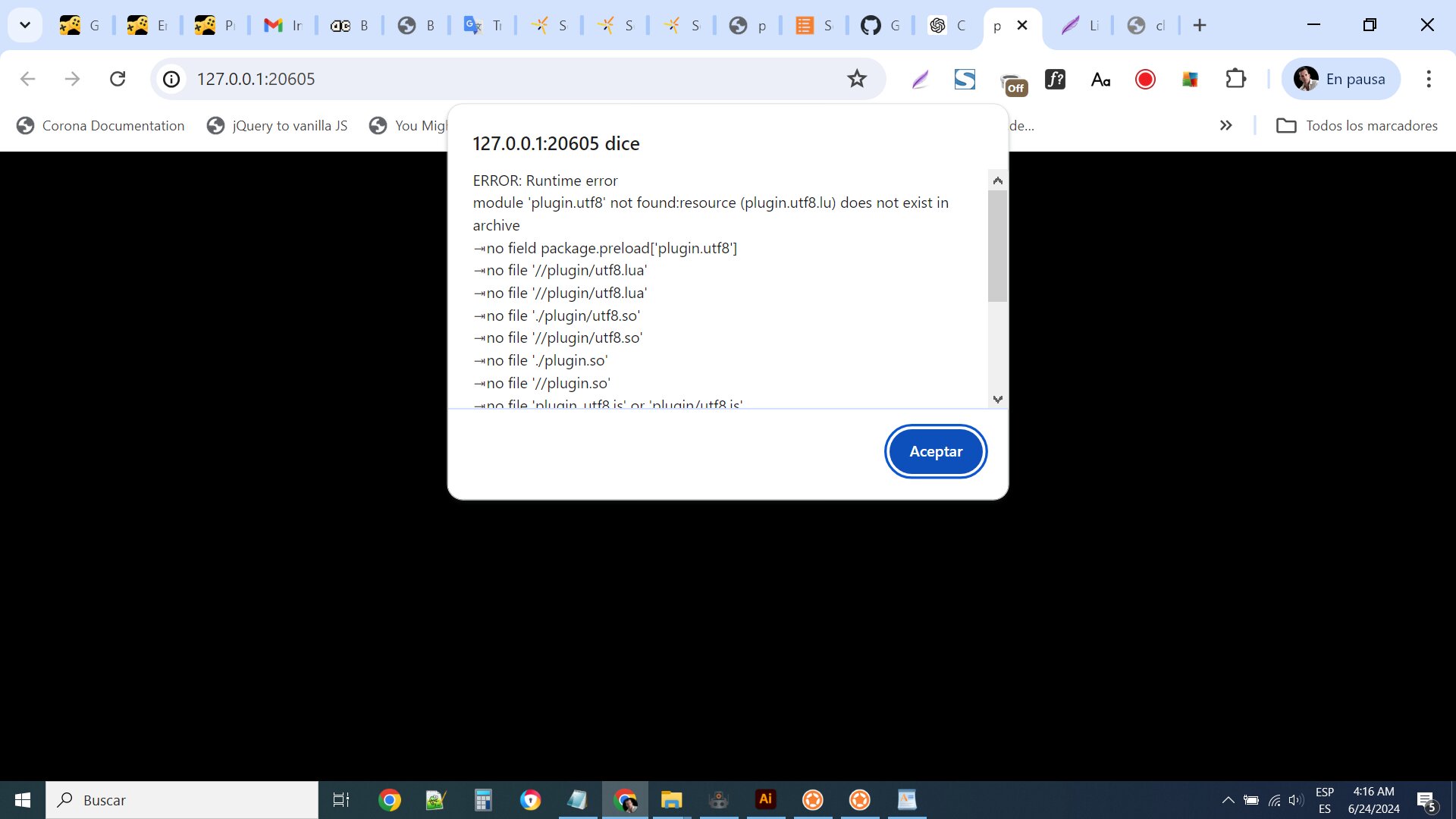
I’m trying to implement the utf8 plugin in a html5 project, but when the build runs on the browser I get this:
My implementation is ok:
my lua file: local utf8 = require("plugin.utf8")
build.settings
{
plugins = {
["plugin.utf8"] = {
publisherId = "com.coronalabs",
},
},
}
the error says that the plugin doesn’t was loaded:
kakula
June 25, 2024, 7:19pm
2
aclementerodrguez:
plugin.utf8
could it be that you need to copy the original lua files to your web folder
Thank you @kakula but it seems that plugin.utf8 doesn’t suport html5 yet… I found this post: https://forums.solar2d.com/t/utf8-plugin-error/347139
I came across the same thing and I found alternative solutions on github, there is no necessary link at hand now. But as a result, I made an assembly from different options that worked for me as a result. If I find it randomly, I’ll let you know, but don’t get your hopes up.
Thank you @Qugurun I found an alternative for the utf8.char method:
utf8 = {}
utf8.char = function(...)
local function encode(code)
if type(code) ~= "number" then
code = tonumber(code)
if not code then
--error("Expected a number, got " .. type(code) .. " (" .. tostring(code) .. ")")
end
end
if code <= 0x7F then
return string.char(code)
elseif code <= 0x7FF then
return string.char(
0xC0 + math.floor(code / 0x40),
0x80 + (code % 0x40)
)
elseif code <= 0xFFFF then
return string.char(
0xE0 + math.floor(code / 0x1000),
0x80 + (math.floor(code / 0x40) % 0x40),
0x80 + (code % 0x40)
)
elseif code <= 0x10FFFF then
return string.char(
0xF0 + math.floor(code / 0x40000),
0x80 + (math.floor(code / 0x1000) % 0x40),
0x80 + (math.floor(code / 0x40) % 0x40),
0x80 + (code % 0x40)
)
else
--error("Unicode code point out of range: " .. tostring(code))
end
end
local chars = {}
for _, code in ipairs({...}) do
if type(code) ~= "number" then
code = tonumber(code)
if not code then
--error("Expected a number, got " .. type(code) .. " (" .. tostring(code) .. ")")
end
end
table.insert(chars, encode(code))
end
return table.concat(chars)
end
…
1 Like